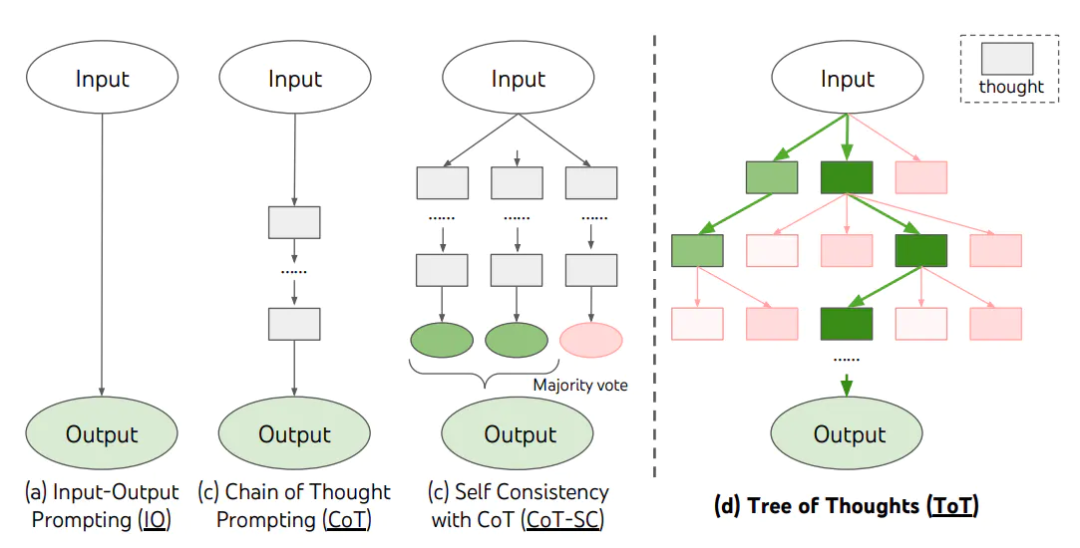
前几天听课,听到老师讲数据列式存储。
我🙋🏻♀️:等等,what,什么列式存储,数据一行一行的展示,然后一行一行的存在数据库里面不就好了,什么叫做列式存储,难道将数据按每一列存在数据库里面,那取出数据该有多麻烦啊,这绝对是几十年前的糟粕方法,这个课听不得了,教的东西太老套了。
老师🧑🏻🏫:别急别急啊,同学,年轻人不要这么心浮气躁嘛,列式存储的存储效率在现在流行的大数据存储中发挥着重要的作用,其存储效率可比行式存储高的多。我先给你举个例子吧。

以学生信息表stu演示。sid为主键,表中记录这五位学生的信息。
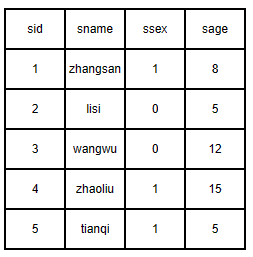
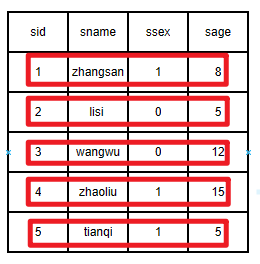
大家比较熟悉的是行式存储,如关系型数据库(MySQL、Oracle等)的存储均采用行式存储,行式存储一目了然,如下图所示,每一位学生的信息存储在存储在存储介质上,先存储zhangsan同学的所有信息,再存储lisi同学的信息,依次存储剩下同学的信息,如下图所示:
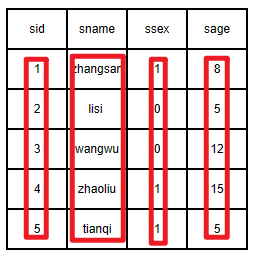
而列式存储,学生的信息数据都是分开保存的,即每一列的数据单独存放,如下图所示,每一列的数据存储在存储介质上,先存储sid这一列,然后存储sname这一列,依次存储剩下的列,如下图所示:
我🙋🏻♀️:好的老师,我已经明白您的背景了,快跟我讲讲列式存储的优点吧。

老师🧑🏻🏫:那就先来一起看看两种存储方式存储在存储介质上的情况吧。
行式存储,每一个学生的信息都存储在相邻的地方,存储完一个学生的信息,再存储下一个学生的信息,以此类推,如下图所示:

列式存储,将每一列的数据存储在相邻的地方,然后再存储下一列数据,以此类推,如下图所示:

老师🧑🏻🏫:现在假设一种场景,我要你帮我取出所有学生的姓名,也就是sname这一列,你会怎么做?
对于SQL语句select name from stu;简简单单,可是在存储介质上取出数据的时候,你知道如何取出吗?
对于行式存储,必须从头到尾遍历存储数据,依次取出sname姓名的数据。

缺点就比较明显了,当我只需要访问几个列时,其他无关列的数据也会被读取,导致IO开销较大;而且数据 **压缩比 **较低,因为每行数据都存储在一起。
对于列式存储,这就简单了,直接定位到sname姓名的位置,就可以直接取出需要的数据了。
在分析型查询(OLAP)中,列式存储通常提供更高的性能。这是因为它只读取查询所需的列,大大减少了IO成本,加快了查询速度。
而且对于同一列的数据类型相同,便于压缩,通常具有更高的压缩比。非常适合大数据存储,如数据仓库,因为它可以快速读取和分析大量数据。

我🙋🏻♀️:等等,MySQL不是有索引吗?我给sname单独加一条索引不就行了,这样查询的时候就可以利用 索引覆盖 的特性,直接拿到这一列的数据了呀!

老师🧑🏻🏫:这位同学,请注意我们现在讲的是列式存储和行式存储,不是在讲MySQL哈。而且像你这样单独给sname加一条索引的做法,其实就是把同一列的数据存储在了一起,也是列式存储的一种应用方式。
我🙋🏻♀️:原来MySQL里也有列式存储啊……

我🙋🏻♀️:再等等,如果我要一个场景,请取出名字为‘zhangsan’的同学的所有信息,阁下该如何应对?
老师🧑🏻🏫:啊这,角色互换了,这样列式存储的效率确实比行式存储的效率低很多了。
对于行式存储,只需要定位到“zhangsan”的位置,就可以直接取出需要的信息;
那行式存储的优点显而易见,对单行数据的操作效率更高,比较适用于事务型查询(OLTP),像频繁的增删改查的操作;当需要访问整行数据时,性能比较高;写入也会比较快,因为一次性完成整行的数据;

对于列式存储,需要从头到尾遍历数据,根据元数据信息,一次取出“zhangsan”的信息。
列式存储的致命缺点就是行事查询、更新和删除操作比较复杂,因为需要处理多个列。而且写入性能比较低,因为需要将一行数据拆分成多个列分别写入。

老师🧑🏻🏫:你这小子,倒也不傻,我看你骨骼清奇,若勤加修炼,日后必得高升,我这有一本数据库修炼秘籍,只要九十九,你看,带不带一本走?
我🙋🏻♀️:6啊,现在的广告真隐蔽。

言归正传,再来正式的聊聊行式存储和列式存储吧。
列式存储比行式存储可以节省多少空间
大家一定非常好奇,列式存储比行式存储到底可以节省多少空间,才让博主绕这么一大圈来讲列式存储。
毫无疑问,列式存储比行式存储具有更高的数据压缩率。根据数据的类型和压缩技术,列式存储可以实现高达十倍甚至更高的压缩比,这意味着,列式存储能够节省大量的存储空间,降低存储成本。

当然,具体节省的空间取决于多种因素,包括数据的重复性,列中数据类型的一致性以及采用的压缩算法。在实际应用中,节省的空间可能会有很大的差异,例如,如果一个数据集中的某些列包含大量重复的值,那么列式存储在这些列上的压缩效果会非常显著。
而对于数据变化较大,不适合压缩的场景,节省的空间可能就不那么明显了。
列式存储和行式存储的区别
说了这么多,那列式存储和行式存储之间还有其他区别吗?
当然有,这区别可是非常大的,你且慢慢看来:
- 结构灵活性:
- 列式存储倾向于结构弱化,更适合于不定长的记录和稀疏数据集,因为它可以有效地处理不存在的列。
- 行式存储则倾向于结构固定,每行数据都需要有相同的列结构。
- 主键存储:
- 行式存储中,一行数据仅需要一个主键。
- 列式存储中,存储一行数据可能需要多份主键,因为每个列都是独立存储的。
- 压缩算法的选择:
- 列式存储可以针对不同列类型,选择最合适的压缩算法,因为每列数据的类型是已知的。
- 行式存储的压缩算法选择不如列式存储灵活,因为它需要处理多种数据类型的混合。
- IO消耗:
- 列式存储在查询时只需要读取参与计算的列,极大地减低了IO消耗。
- 行式存储在读取少数几列时,需要遍历其他无关列,IO开销较大。
- 数据更新:
- 列式存储不适用于数据需要频繁更新的交易场景,因为每次更新可能涉及多个列的变更。
- 行式存储更适合频繁更新的场景,因为整行数据通常是连续存储的。
拓展:ORC存储
另外,向大家推荐一种存储方式,即ORC存储,也叫混合存储结构。
ORC(Optimized Row Columnar)是一种高效的列式存储格式,最初由Apache Hive项目开发,用于优化Hadoop数据存储和查询速度。它并不是纯粹的列式存储,而是采用了混合存储结构,先按行组分割表,然后在每个行组内部按列存储数据。ORC文件是自描述的,其元数据使用Protocol Buffers序列化,且数据尽可能压缩以减少存储空间消耗。
ORC文件的主要优势包括:
- 高压缩比:列式存储运行多种文件压缩方式,提供很高的压缩比;
- 文件可切分:便于在Hive等系统中分布式处理。
- 索引支持:提供多种索引,如row group index和bloom filter index,以优化查询。
- 复杂数据结构支持:能够处理如Map等复杂数据类型。
ORC文件结构包括多个层级,如文件级元数据、stripe(包含多条记录的行组)、stripe元数据和row group,这些结构支持有效的数据读取和查询优化。例如,ORC利用三个层级的统计信息来实现谓词下推,从而避免读取不必要的数据,提高查询性能。
后记
这篇关于数据的行式存储和列式存储,其实是我女朋友在学习大数据知识的时候了解到的,我个人对这块也只是一知半解,如果文中有错误的地方,欢迎大家在评论区指出。











![[柏鹭杯 2021]试试大数据分解?](https://img-blog.csdnimg.cn/direct/f2684e35f6854d7e8ca5fe2ca763b9a1.png)